清华大学研发LLM4VG基准:用于评估LLM视频时序定位性能
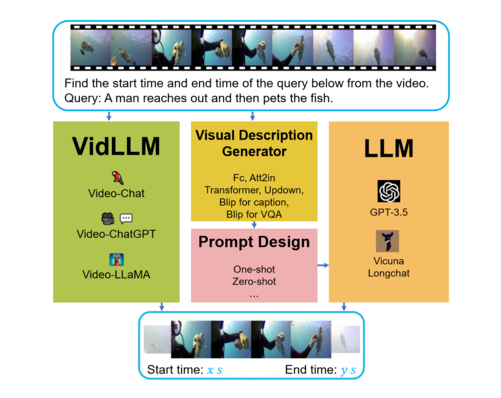
近日,大语言模型(LLM)在视频时序定位(VideoGrounding。VG)领域的应用引起了广泛关注。这项任务的目标是在给定查询后,在目标视频段中准确地确定起始和结束时间。虽然直接在视频内容上进行训练的VidLLM在实现令人满意的VG性能方面存在差距,但结合了传统的LLM与预训练的视觉模型的第二种策略却表现出更好的效果。
研究团队推出了专门用于评估LLM在VG任务中的性能基准“LLM4VG”。该基准考虑了两种主要策略:第一种策略涉及直接在文本视频数据集(VidLLM)上训练的视频LlM;第二种策略则是将传统LLM与预先训练过的视觉描述模型相结合。
VidLLM直接处理视频内容和VG任务指令,并根据其对文本-视频的训练输出进行预测。尽管如此,这一策略在实现令人满意的VG性能方面仍有一定差距。然而,第二种策略优于VidLLM,在未来的研究中具有很大潜力。这种策略主要限制于视觉模型的局限性和提示词的设计,因此能够生成更详细且准确的视频描述。此外,更精细的图形模型可以进一步提高LLM在VG任务中的性能。
总之,这项研究对LLM在VG任务中的应用进行了开创性的评估。并强调了在模型训练和提示设计中需要更复杂的方法。这些发现为今后研究提供了有益的启示。